This is the first blog post in what will be a series of posts on retrieving, formatting, querying and visualizing data from the USDA National Agricultural Statistics Service (NASS). To understand what kinds of data we'll be working with, we can take a gander over to the NASS quickstats website at https://quickstats.nass.usda.gov/. The homepage brings up a rather innocuous design:
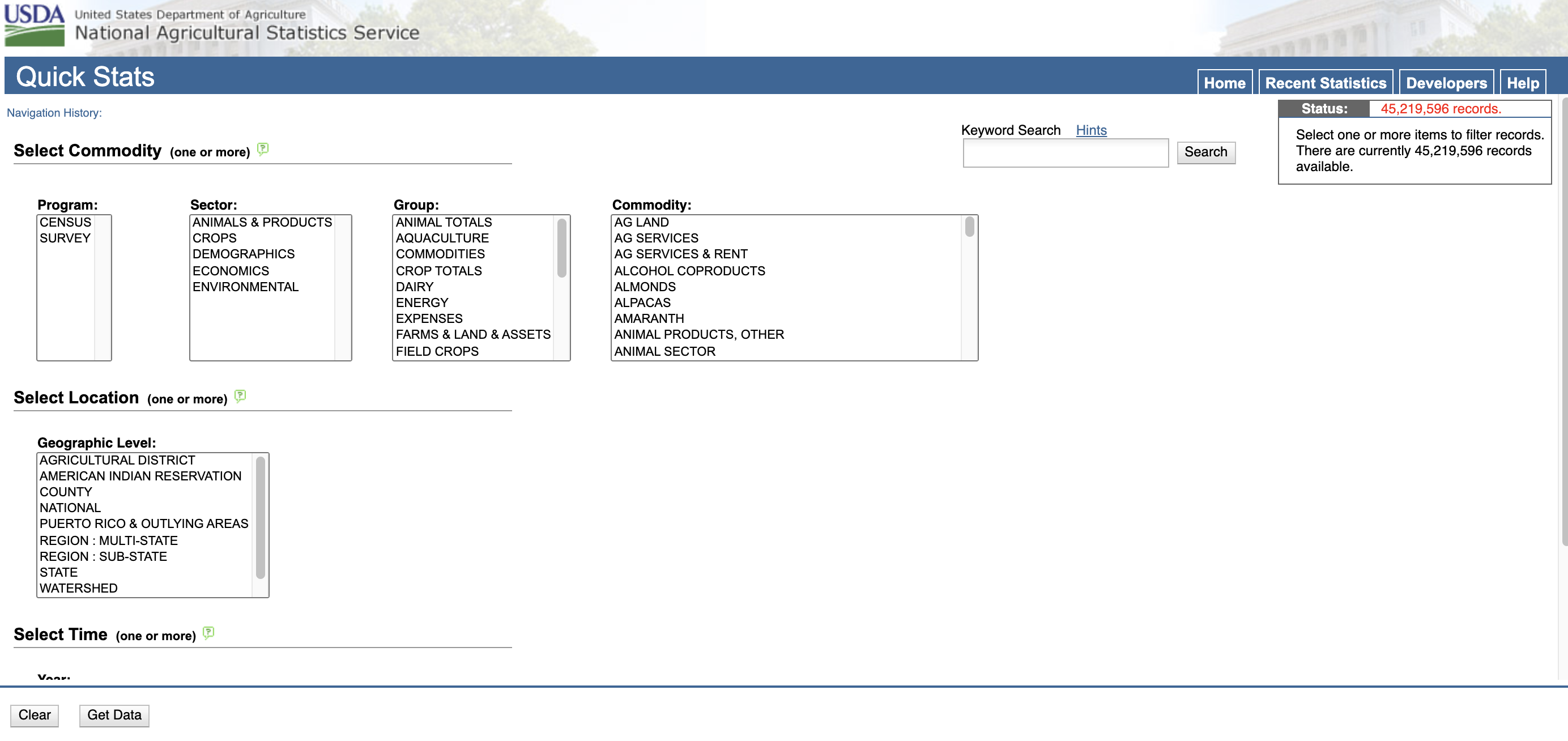
You can pick from a variety of options that generates a dataset for perusing. It will be displayed after selecting the Get Data button at the bottom left corner of your browser window. Once you've created some data, you can download a CSV file with all the selected values by clicking spreadsheet in the top right corner of your window. Unfortunately, we're only able to work with datasets that contain a maximum of 50,000 records at a time.
I don't know about you, but any CSV/Excel file over 500 rows is virtually impossible for me to handle in a coherent manner. It's not a fun way to operate and it doesn't scale if you want to look at the millions of records contained in the NASS database. Instead, we're going to use the NASS API to request our desired data and combine it programmatically. The API gives us the ability to build a much larger dataset. It's also our first step in the process of building a dataset to analyze.
Let's jump start this journey by first navigating to the Developers tab located in the top right corner. After that, select Request API Key on the left. Once all the steps are followed, we'll receive a key, via email, that must be provided to each HTTP Request in order to retrieve the data we desire. It's good practice to set keys as variables in your terminal's shell. As an example, I'll set this key to the variable name: USDAKEY. Setting values like this to the shell environment allows quick retrieval and exporting to common applications, like Jupyter, when programming. More importantly, it prevents the hard coding of sensitive credentials. In the next post, we're going to build some infrastructure using Amazon Web Services to handle the data we retrieve from the NASS datbase.